Summary
The streaming sync method involves listening to events from Salesforce’s pub/sub API and a log of Postgres events, then transacting any events using the REST API and SQL. The benefits of streaming are faster syncs (max 30-second latency), optimized Salesforce API usage, and less data stored on Bracket’s servers. Under streaming, the only data Bracket stores on its own servers is a list of primary keys corresponding to unprocessed records from Salesforce, which helps us retry any failed record syncs. This data can also be self-hosted on your servers. This is the format of theunprocessed_records table:
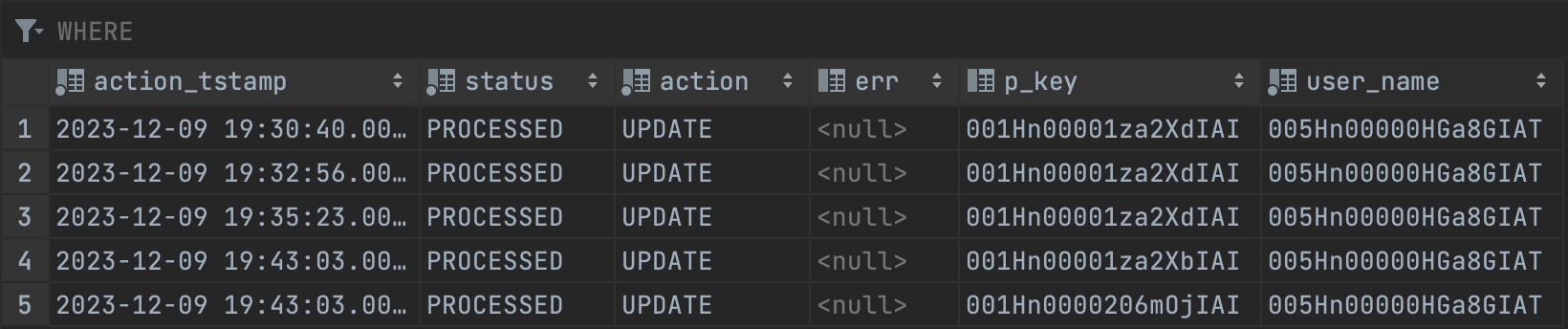
Right now, streaming is only available between Salesforce and Postgres, and only on the enterprise plan. Reach out to us at eng@usebracket.com to learn more.
Requirements
Salesforce
- Bracket must have a dedicated Salesforce account with the correct permission. This helps us separate valid user edits from changes synced by Bracket.
- Salesforce must be the primary source, meaning it will win any merge conflicts
- The synced Salesforce object must have a unique
Idfield. In most objects, this is automatic.
Postgres
- There must be a separate schema called
bracket_audit. This is where Bracket will store the trigger log table, which contains a history of Postgres events.
Create schema statement
- Bracket must have a dedicated Postgres user with the permissions below:
Create user statement
- Any synced table has
bracket_pkeyas the primary key field, with UUIDv4 values. Bracket will generate these for you for any created tables. - Any synced table has a field called
id, which syncs with the Salesforce ID field. - You should see the following sql executed in your postgres:
The streaming sync method, step-by-step
At cadences as fast as every 30 seconds, Bracket performs the following:1
First Step
Bracket checks the Salesforce pub/sub API to see if any events have occurred since the last
successful data read/write. E.g., if the last change read by Bracket on your Salesforce
object was processed six minutes ago, Bracket will only check the pub/sub API for any events
with a
commitTimestamp greater than the last six minutes.If there are no new events, and it’s been less than 10 minutes since the last successful
poll, Bracket does not poll Salesforce—this is where Brackets saves you from costly REST
API usage.2
Second Step
If there are events reported by the pub/sub API, or if it’s been greater than 10 minutes since the last poll, Bracket polls Salesforce via REST API for all records modified or created since the last successful poll. We store these records in
unprocessed_records.Consistent 10-minute polling intervals make sure any events missed by pub/sub are still ultimately synced.3
Third Step
Bracket reads records from the Postgres trigger log that have
status='UNPROCESSED' and queries records with the corresponding primary keys from the synced Postgres table.4
Fourth Step
Bracket writes Salesforce edits to Postgres. The record is then marked as
PROCESSED or
ERROR in unprocessed_records. If ERRORED, Bracket will try syncing the erroneous
record at the next poll attempt only if a new change has been detected.If during a given sync period a corresponding Postgres record was also updated, Bracket will remove the record from the next step.5
Fifth Step
Bracket writes Postgres edits to Salesforce. For inserts, which don’t yet have a Salesforce
ID assigned, Bracket makes a “round trip”, capturing the newly-created SFID in the insert
response and updating the Postgres record with it.